Developer Day 2017 (DDD12)
Only a month after the last DDD in Bristol, we've now just had DDD-12, which was hosted at Microsoft's Reading headquarters in the Thames Valley Park! <--->
I was running a little bit late, so once I arrived I only had 5 minutes to quickly grab a coffee before going into the Chicago 1 conference room for the first talk of the day!
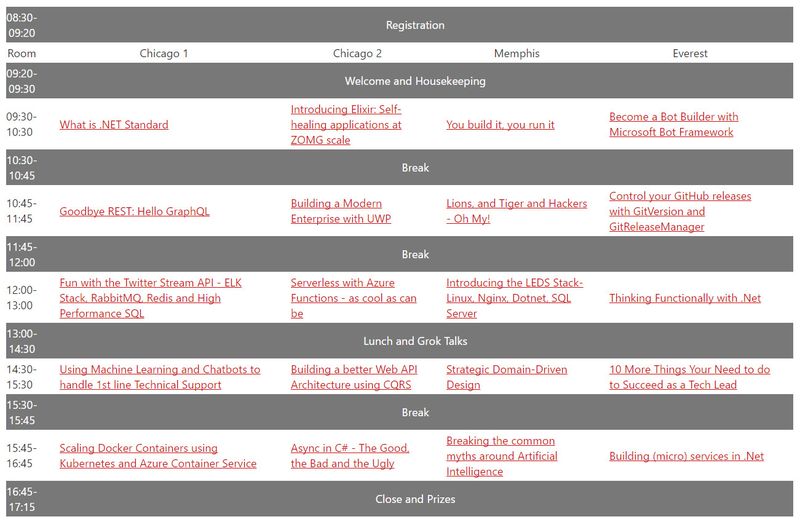
Before arriving, I had looked through the agenda and had a vague idea of which talks that I was going to attend. There were concurrent talks that I really wanted to see, but unfortunately without the power of mitosis, I had to choose! As you can see from the agenda below, there were some tough decisions to make!
Adam Ralph: What is .NET Standard?
The first talk I went to was by Adam Ralph, talking about .NET Standard. Whilst I already had a fairly good understanding of what it was, Adam went deeper under the hood explaining how it works, introducing the Netstandard.dll and how type forwarding brings all the magic together.
Adam started off explaining the problems with portable class libraries, and using lots of bizarre and funky looking venn diagrams to help demonstrate these issues.
There are lots of different implementations of .NET - Silverlight, Xamarin, .NET Core, .NET full framework, etc. With PCLs, you choose from a list of these implementations. The more you target, the less compatibility your library had.
He then moved onto explaining the .NET Standard, how it works. We no longer explicitly reference a implementation of .NET - but we just reference a .NET standard version. Then it's up to the different .NET implementations to keep up with the standard, and you as a library developer do not need to worry about implementations - only the .NET Standard abstraction. For those who know their SOLID principles, it feels very similar to the ideas behind dependency inversion!
Adam then explains the issues we've had this past year with the initial 1.x versions. These early versions of the standard have a much smaller API coverage than the newly announced .NET Standard 2.0, which now brings a much higher surface level of the .NET APIs and removes most of the compatibility issues we've seen this past year. He even demoed referencing an old .NET 2.0 library (PowerCollections) from a .NET Core application!
It certainly does feel like with the introduction of .NET Standard 2.0 - a lot of the headaches I'm sure a lot of us have felt this last year should go away. I tend to think of .NET Standard as being like an interface in .NET and the various .NET platforms being the implementations. That interface has now got a whole lot bigger adding much more functionality. However, as it's an abstraction - then you now longer need to care about the .NET implementations when creating a library in .NET. Start with the lowest .NET Standard version you can, and only increase that number when you need extra functionality in your library.

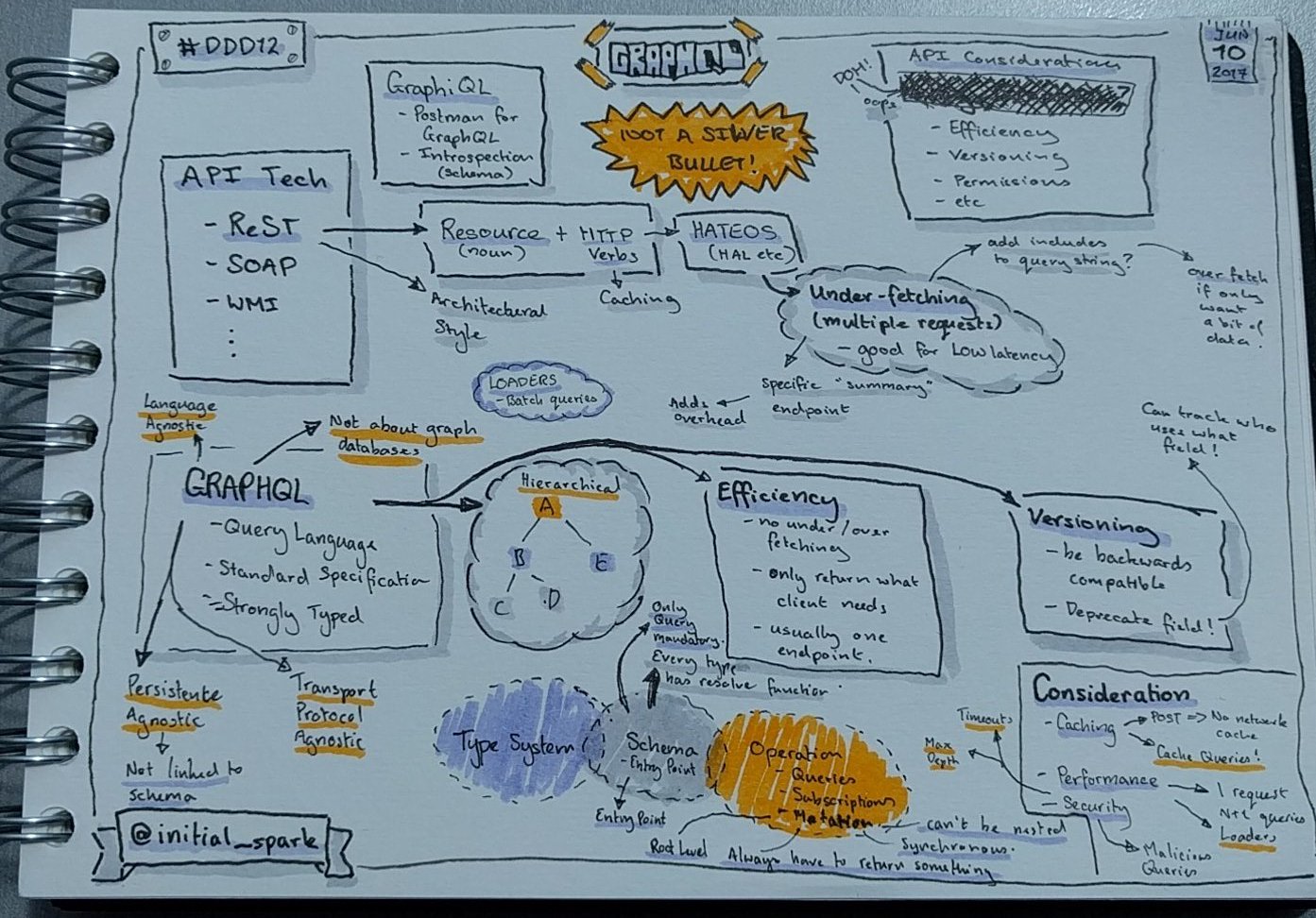
Sandeep Singh: Goodbye REST; Hello GraphQL
I've been hearing a lot of things lately about GraphQL and had a vague idea what it was about - but really wanted to actually see it in action! So Sandeep's talk was an obvious choice for me, and it appeared that a lot of other attendees thought exactly the same - as this session was completely chocca! With lots of people having to stand along the side and at the back!
He start off briefly mentioning REST, then quickly moved on to explaining what GraphQL is all about. It's basically a query language for your API - which allows the client to tell the API what data it requires. This gets around a number of problems that we commonly see when we use standard REST APIs. Some examples Sandeep discussed were under-fetching (having to make multiple API calls to get and compose the required data); over-fetching (endpoints returning more data than you actually need); and having to manage lots of different ad-hoc endpoints rather than just one which you can query against.
Sandeep then moved on to showing how GraphQL gets around these issues by allowing the client to tell (query) the server what data it needs. This would also typically just be a single endpoints, rather than having to manage a long list of endpoints. The latter bit of his talk was a demo allowing us to see GraphQL in action, and seeing how you use resolvers to compose the data on the server-side. The key point being that the datasource doesn't matter and isn't really a concern of GraphQL - it's down to you on the serverside to query the relevant data in your resolvers, then GraphQL will compose it all together based on data the client has requested. Also, the data is strongly typed - so the tooling (eg. GraphiQL) can give you intellisense and type checking.
A very interesting technology, and definitely now very high in my list of things to play around with! I can certainly imagine you'd have to be quite intelligent with how you managed caching on the serverside though. It feels like it would be very easy to move the over-fetching problems to the server and have lots of performance issues that you're not even aware of!

Alex Brown: Introducing the LEDS Stack - Linux, Nginx, .NET, and SQL Server
Wait? What?! .NET, SQL Server AND Linux?! Well, that's perhaps something you might have said 5 years ago - but we've all seen what has been happening with Microsoft lately with their commitment to both open source and cross platform - so the introduction of a new stack like this should no longer come of a surprise!
Alex starts of explaining what each of these components is, as well as talking about Entity Framework, as this is the ORM he uses to communicate with SQL Server. One of his core goals for the demo was to use as few Microsoft tools as possible. Although, he openly admitted that he was going to break his rule by using VSCode (and as we're all huge fans of VSCode, we're not going to hold that against him!). To manage the database side of things, he introduced us to Jetbrains DataGrip. Coincidentally I only learnt that this was a thing a few weeks ago. Unfortunately I haven't had much luck getting it to work with SQL Server on Windows - but Alex's talk has definitely prompted me to try again!
He then discussed a few options of IDEs we have when developing in this new cross platform .NET world! First talking about the newly announced Visual Studio for Mac, then VSCode, and then Jetbrain's cross platform .NET IDE Rider!
You may have noticed that I said Visual Studio for Mac in the last paragraph. Yes, all this was done on a Mac, not Linux - the point being that the deployed production version was running on Linux. Alex used a Digital Ocean 'Droplet' - which is just their name for a hosted VM. Whilst demoing this locally, he was using the .NET CLI running on his Mac, and SQL Server running in a Linux Docker container.
The end of the talk demoed his application being deployed to production (the Digital Ocean droplet), and I loved the relief that was clearly visible on Alex's face when it ran perfectly the first time on prod. You could tell he expected the demo gods to start poking around :)
A great talk, and it really showed how much things are changing in the Microsoft space. I've said this quite a lot lately, but now is such a great time to be a .NET developer!

Lunch
The lunch break was primarily taken up by watching the lightning talks - however we did have about half-an-hour to enjoy both the lunch packs kindly provided, and also the blazing sunshine! I sat with Robin Minto, and enjoyed talking security and persuading him to do a talk at our .NET Oxford lightning talk meetup next month! Speaking of which, if anyone reading this is also interested in doing a 10/15 minute talk, please get in touch!


Grok Talks
After we finished our lunches, we moved back inside to watch the lightning "grok" talks ...
Gary Short: Markov, Trump and Counter Radicalization
The first grok talk was by Gary Short, talking about Markov, Trump and Counter Radicalization. He talks about what radicalisation is, and why it's hard to counter. He discusses using Markov chains to process known text, and even gives us an example of this with his C# application Tweet like Trump which takes existing text from Trump, and generates (wait for it!) ... Tweets like Trump!
A video of his talk can be found here.
Ian Johnson: Sketchnotes
The next grok talk was by Ian Johnson, talking about his sketchnotes.

These are incredible, and it's amazing that he's actually taken these notes whilst listening to the talk he's making the notes about, and not after the fact! In his talk, he explains how he does it, and gives tips on how to do it yourself. He stresses that he's not an artist, and he just follows a few simple rules ...
- Practice your handwriting
- Don't be afraid to make mistakes, as you can cover them up easily with other notes
- Don't worry about spending time colouring - this can be done later
- Keep certain bits in the same place on each page - eg. speakers twitter handle, date, topic, etc. This means that you can flick back through your notebook to find something.
Ian has blogged about his sketchnotes here; and he's also blogged all of his sketch notes from this DDD12 conference here!
Christos Matskas: Becoming an awesome OSS contributer and maintainer
The next grok talk was by Christos Matskas talking about how to get into Open Source. He starts off talking about why you'd want to, and gives examples of the benefits, some examples he gave are:
- Great networking potential
- Becoming a better developer
- Getting free stuff! A lot of software companies let open source projects use their products for free!
- It looks great on your C.V. You have something tangible that potential employers can see you have done
He then talks about how to get started, and points us at some resources for first timers:
He stresses that being an open source contributor doesn't have to mean writing and understanding masses of very complex code - it could even just be updating documentation when you see mistakes.
Then he finishes off talking about guidelines from both a maintainer and a contributor's point of view. A maintainer should always create guidelines so contributors know the standards for that project. Likewise, a contributor should always try and follow guidelines and keep their code consistent with the project.
Rik Hepworth: Lability
The last grok talk was by Rik Hepworth talking about Lability, a Powershell module which allows provisioning of Windows Hyper-V development environments using Desired State Configuration. This extends Powershell Desired State Configuration, allowing you to specify in one file all the information required to provision the VMs - both machine details and also the software installed on them.
Joseph Woodward: Building a better Web API Architecture using CQRS
I first met Joe at the DDD conference last month in Bristol with his Razor Deep Dive talk, which certainly taught me a lot about something I already thought I was comfortable with! This time, Joe talked about the CQRS design pattern, and using the MediatR library to help structure your code, and enforce very loose coupling.
Joe begins by explain what the CQRS pattern actually is. It's an acronym standing for 'Command Query Responsibility Segregation'. The main idea is that you separate the code that reads from the datastore(s) and the code that writes to them.
A Command is in charge of writes. It can mutate state, and typically doesn't return any data at all. Although, apparently not returning any data is heavily debated, as you quite often need to return IDs when creating new entities. One of the attendees even raised their hand saying that they use CQRS, but do return IDs, as it wouldn't make sense to not.
Given a command usually doesn't return data, then this means that a command can also be a message put onto a queue, which is another advantage of this separation. When going over HTTP, the command will deal with the following HTTP verbs: POST, PUT, PATCH, and DELETE. The command is also where you'd tend to attach your validation to, as opposed to the query.
A Query is in charge of reads. There is no state mutation involved, and more often that not, validation is not required for queries, as they've come straight from our datastore(s). When using an HTTP endpoint, a query is typically associated with a GET request.
An example that Joe gives shows an ICustomerService with lots of read and write methods. He then shows it split out into two separate interfaces: ICustomerWriteService and ICustomerReadService, explaining that this separation helps enforce smaller, less 'do everything' kind of services / repositories.
Joe then introduces the MediatR library, written by Jimmy Bogard, and mentions that he even designed the logo for this library! He also mentions the Brighter library, however his demos and main focus is around MediatR.
The idea being that you register both the mediator, and your handlers with whichever IoC container you're using. Then you can inject them into your code where required and access the data in a very consistent clean manner always going through your handlers. You can also chain handlers into a pipeline to support validation, logging, notifications, etc. without breaking the Single Responsibility Principle.
Joe then wraps up discussing 'Feature Folders'. This is an alternative way of structuring folders in our projects so that all the files relating to a particular feature are kept together. So a prime example is with MVC where the default folder structure is to have all the Controllers together in one folder structure, all the Models together in another folder structure, Views in another, etc. With Feature Folders, we change the structure so that we have a folder named after the feature we're working on, and it it we keep the controller, model, view, etc. together. Generally a developer is working on one particular feature at a time - so it makes sense to keep this together. It also makes it far easier to glance at a project and see where you need to be. Another benefit that I really like is that you can just open that folder in your IDE rather than opening the entire project. Visual Studio has the 'Scope to this' right-click option in its Solution Explorer allowing you to just show what's in a specific folder. Other editors probably support similar - or you can just literally open that one feature folder if using an editor that supports opening folders (eg. VSCode, Sublime, etc).

Ben Hall: Scaling Docker Containers using Kubernetes and Azure Container Service
It was getting close to the end of the day, and I hadn't yet been to a talk about containers! Something had to be done! And who better to do this than Ben Hall himself, creator of the fantastic interactive learning platform Katakoda.com! If you're interested in containers, then I'd definitely recommend checking out his site.
I'm a huge fan of Docker, and whilst I haven't used it in production - I do use it a lot for local development. I was bracing myself for yet another back to very basics talk. Whilst Ben does explain containers, images, layers, the Dockerfile format, etc. - he does cover a lot of detail in a short amount of time, and you can tell that he assumes his target audience is quite technical and kind of already knows the basics. I don't think anyone no matter how much they already knew about Docker was falling asleep in his talk!
Ben then talks about advantages of containers in different scenarios - eg. scaling containers individually; in a build/deployment (CI/CD) pipeline the build agent no longer needs all your app's dependencies installed - as they're self-contained in the images; etc, etc.
He demonstrates using a .NET Core application in Docker, and talks through the different commands in the Dockerfile.
He also introduces a new DockerFile feature called Multi Stage Builds. This allows you to have multiple DockerFile command lists in the same file. This is the example in his slides ...
# First Stage
FROM microsoft/dotnet:1.1.1-sdk
WORKDIR /app
COPY dotnetapp.csproj /app/
RUN dotnet restore
COPY . /app/
RUN dotnet publish -c Release -o out
# Second Stage
FROM microsoft/dotnet:1.1.1-runtime
WORKDIR /app
CMD ["dotnet", "dotnetapp.dll"]
COPY out /app/Which is incredibly useful, as the size of some of the base development images tend to be much larger than you'd need or want in production! So having two versions in the same file is a huge step forward.
He then talks about image repositories and how you can use them to share your images. You have Docker Hub, and you can also spin up your own in Azure! Plus many more options.
Now is the bit that I'm particularly interested in - KUBERNETES! This is a container orchestration engine / platform originally created by Google. This was born from Google's internal Borg and Omega systems, and is now controlled by the Linux Foundation. It has become one of the most popular container orchestration systems available today.
Ben shows how to set up Kubernetes very easily using Azure Container Services. He also mentions the other orchestration options in ACS (eg. DC/OS and Docker Swarm).
This tweet from his slides shows how easy it is to setup Kubernetes on ACS - even from an iPhone!!!

Ben then talks about what Kubernetes actually does - discussing the way it uses desired state configuration and monitoring to ensure that the state of the environment always matches your desired state. He talks about using Prometheus and Grafana for monitoring and visualisations.
He finishes talking about Windows Containers, and also the future of containers in general - eg. will we see all our apps in containers? Visual Studio for example?

Further Reading!
If you've made it this far, well done! I thought this was a fairly long blog post until I saw that a fellow attendee Craig Phillips has written a much longer one! So if you're looking for a bit more detail, or want to read about some of the sessions that he went to, but I didn't - then definitely check out his epic post here!
Channel 9 Videos
There were also some interview videos recorded on the day whic have now been published on Channel 9!
Wrapping up
After the very last session, we all gathered in the foyer for the closing talk and the prize draws. I had my fingers crossed for one of the NDC London conference tickets - but sadly to no avail! A big congratulations to all the attendees that did win though!
Outside before heading home, I caught up with Joseph Woodward and Stuart Lang, which turned into quite a long conversation discussing various technologies and running user-groups! I also picked Joe's brains for speaker ideas for .NET Oxford, and came away with a few ideas and people to get in touch with that his .NET South West have recently had.
So then it was the journey home back to good ol' Wantage, and I arrived home just in-time to see my amazing kids before they went to bed. A great day had by all! If you haven't been to one of the DDD conferences, then I'd highly recommending going along to the next one - hopefully I'll see you there!
Comments